Reinforcement Learning
Supervised learning = Teaching by example we have a dataset with labels.
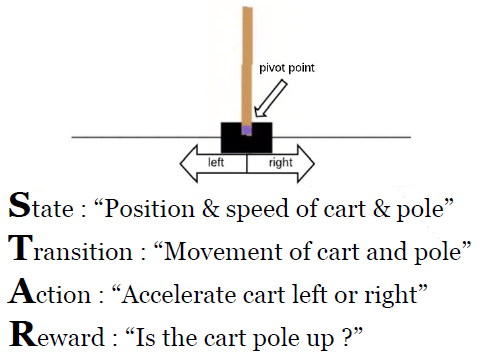
In Reinforcement Learning there isn't labels, the network learn by experiences things. Without label, we decide to use Markov Decision Process (MDP) represented by 4 objects STAR : State, Transition, Action, Reward
MDP : STAR
- State : state = S [what state I am?]
- Transition : nextState = T(state, action) [Transitions can be deterministic or stochastic]
- Action : possibleActions = A(state) [What can I do]
- Reward : reward = R(state, action) [did I achieve my goal? Get close? Get far?]
TOOLS
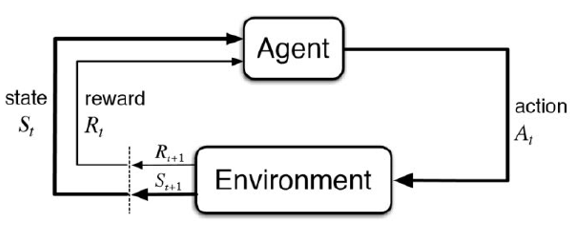
Reinforcement learning is a fundamentally iterative process : Agent acts, Environment computes transition and again. S&R are in agent, A&T are in environment.
- Policy : 𝝅 : “In every State, what action do you chose ?”
- Good policy yields the agent a lot of rewards
- Objective : 𝝅* which maximizes the rewards
- Return : "How good is the state"
- High value : close to a reward // Lower value : far to a reward
- Value function : V𝝅(s) "how good are all state ?"
- Quantifies the amount of reward an agent is expected to receive starting in s and following 𝝅.
- 𝝅=f(Value Function)
Learning
- Start somewhere & initialize V at random
- compute 𝝅=greedy(V)
- Estimate V given 𝝅, V represent the actual values of the states.
- Repeat from Step 2 until convergence.

To express Value function from rewards instead of returns we use Bellman's Equation.
Canonical Algorithms
Two types of algorithms Monte-Carlo or temporal difference (ON-Policy or OFF-Policy).
Monte Carlo has some limits : learning happens at the end of the episode and sometimes training could never end (especially the first ones).
We will treat those two in our example which are TD algorithms:
 |
| SARSA algorithm // ON-Policy |
 |
| Q-Learning algorithm // OFF-Policy |
An example : Cart pole
Here is a link to see the code. I encourage you to follow the step with
Imports
Gym library is a toolkit for developing and comparing reinforcement learning algorithms. In our case we will use Cart Pole. We can see its STAR in the code :

Define AgentNeuralNetwork
It's implement a QNetwork :
First you define the layers and then how they're used :
- Init : initialise the network
- Activation function "sigmoid" or "LeakyReLU"
- Dropout
- 5 linear layers (fully connected).
- Output layers : one for each action (in our case 2 left or right)
- 2 functions to define spaces
- Forward function which gives for each state the score of each action (did I go left or right?).
- Q : If A is specified, the specific value is returned. If not, all values are returned.
For each given state we have : the value of action 0[go to the right] and 1[go to the left].
Define Doer
The class which do something. These class need a model (what we did before).
- Act : do an action
- Everything is okay with the state ?
- A chance of act randomly (value of epsilon=0.1 : 1 time by 10 I act randomly)
- It uses what we did before and take the index of the maximum.
End with some tests. qValues : [ 0.2...., -0.001... ] I do action 0.
Define Transition
A function which encapsulate all the relevant data about the transition :
- State
- Action
- Reward
- The next step
- The next action
- isTerminal
- ID [identify the transition]
- relevance [do I learn a lot by this transition?]
- birthdate [order of appearance]
Define Experience Replay
This class will contain all our transitions.
- Init : initialise it
- BufferSize
- BatchSize
- weightedBatches : Transition more relevance will be selected more
- sortTransition : when the buffer is full did I remove the oldest one or the less relevant.
- Remove & Add Transtion
- sampleBatch : return a number of transition
Define Learner
This class will permit to train our Q-network based on batches in Experience Replay.
- Init : qNetwork, Spaces (stateSpace & actionSpace), Gamma & Algorithm
- Save your action spaces
- Target network (train) & Frozen one (to compare to it, did I learn well).
- Gamma : discounting facture
- Algorithm : "SARSA" or "Q-LEARNING"
- optimizer : SGD or Adam
- cleanBatch : verify if batches are ok.
- computeTarget : the value that you want to achieve, depends on the algorithm
- learn :
- Verify
- Clean batch
- Extract object from batches
- I activate the target network training / define the current value / the target
- Update the weights [computing errors]
- UpdateFrozenTarget, target become frozen and we go again.
For this one the test is more complicated:
- Set-up :
- create a model, a doer and an Experience Replay
- then make state_0 & action 0
- Do one turn : action_1, state_1, reward_1, terminal_1 ==> transition 0
- ER.append(Transition_0)
- 2nd turn : action_2, state_2, reward_2, terminal_2 ==> transition 1
- ER.append(Transition_0)
- create a batch : manually to avoid stochasticity of batch creation.
- Show that target and targetFrozen networks are different :
- print before train, learn, print again
Training Loop
Initialise training : initialise allthe cells we have done before : qNetwork, doer, learner, ER
- Training Loop - Note that you need to stop it manually.
- counting (iteration)
- save the action
- computing the new action
- save the state
- compute the next step
- transition
- for every ER, I add the transition, sample a batch and learn
- update filtered measures
- print what is going on and then reduce epsilon
- update frozen target network
- at the end : reset env and update the score
Evaluation
First cell plot the reward and score all the time. The Second cell, display the transitions for one episode

Example of what I obtain without touching any
Renderer
Print a little video of what your agent does.
We just finish the explanation of the algorithm let's try to optimize it by changing parameters :
- Activation function [network]
- Type of algorithm [learner]
- Optimizer [learner]
- Initialize training [Training Loop]
Parameters/Experimentation :
I store in this table the result of our agent with 5 minutes training, for each parameter we kept the best one to achieve the best result :

Note that random doer as good results because to do right-left-right-left is a good tactic.
To conclude to obtain 40 steps with the highest score of 12 :
- Activation function : LeakyReLU
- Algorithm : SARSA
- Optimizer : SGD
- Experience Replay
- batchSize=16
- sortTransition=True
- weightedBatches=True